Managing Configuration in Microservices

Software Engineer - Backend
Configurable Services & Externalized Configuration Pattern - Motivation
Services need configuration properties to run - network location and credentials of databases, network location of message brokers, third party services, and so forth. The values of these configuration properties depends on the environment the service is deployed on. For e.g., development and production environments use different database/broker instances, hence corresponding configuration property values are different.
It is impractical to consider hardcoding these configuration property values in service code because then they become a part of the deployable artifact. We would be, therefore, required to build a separate artifact for every environment. Ideally, a service should be built only once by the CI/CD pipeline, and the artifact should be deployable on multiple environments.
It also does not make sense to hardcode different sets of configuration properties for different environments in the source code. Whilst we can use some mechanism to select the appropriate set of configuration properties at runtime for each environment (by using Spring Profile for instance), it may not be a good idea because it risks introducing security vulnerabilities, for e.g. - database credentials and other sensitive configuration values would lie around in the source code which most probably would be versioned and shared through a repository. Secondly, if we want to add a new deployment environment, we shall have to add a new set of configuration properties to the source code - this is visibly inefficient, and also sidetracks and pollutes the code base.
Therefore, we should use the Externalized Configuration Pattern - make configuration properties available to the service based on the deployment environment.
Two Main Approaches for Implementing Externalized Configuration Pattern
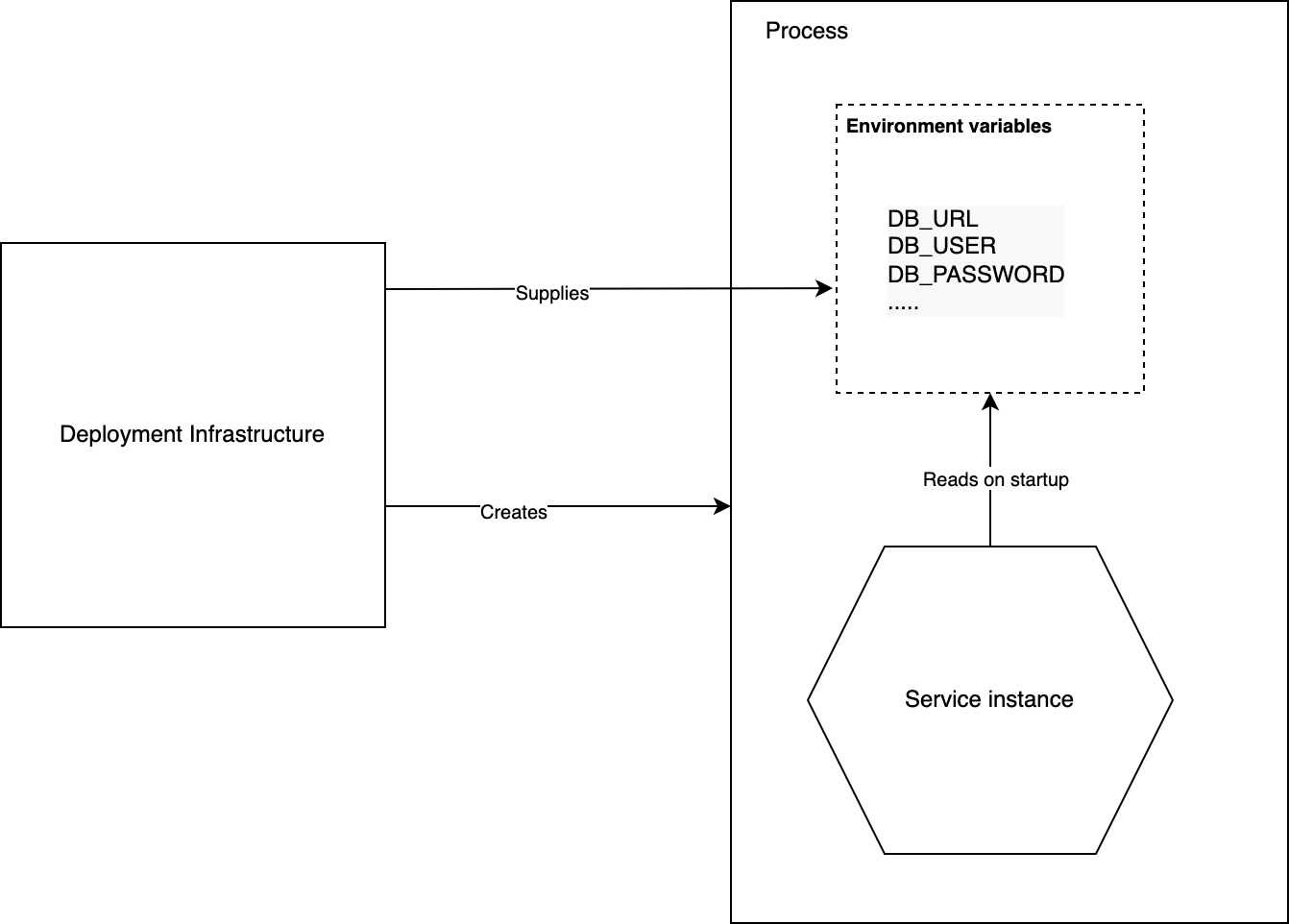
Push Model
- The deployment infrastructure supplies the configuration properties when it creates the service instance. It can pass the configuration properties as OS environment variable(s) or configuration file(s).
- The service instance reads the configuration properties when it starts up/is starting up.
- The deployment infrastructure and the service need to agree on the supply and consumption of configuration properties. If they are supplied as environment variables, the application should have a way to read those variables (System.getenv() in Java) or some framework that provides a more convenient mechanism. For e.g. - Spring Boot reads configuration from different sources and has well-defined precedence rules between them. The configuration properties are made available to the Spring ApplicationContext which can be obtained using the @Value annotation - Read more about it here.
- Configuration properties across multiple services can be centralized by using a version controlled configuration repository coupled with deployment tools like Helm for K8s, otherwise we may run into a risk of configuration properties being scattered throughout the definition of numerous services.
- The following image roughly represents how the Push Model for externalized configuration works:
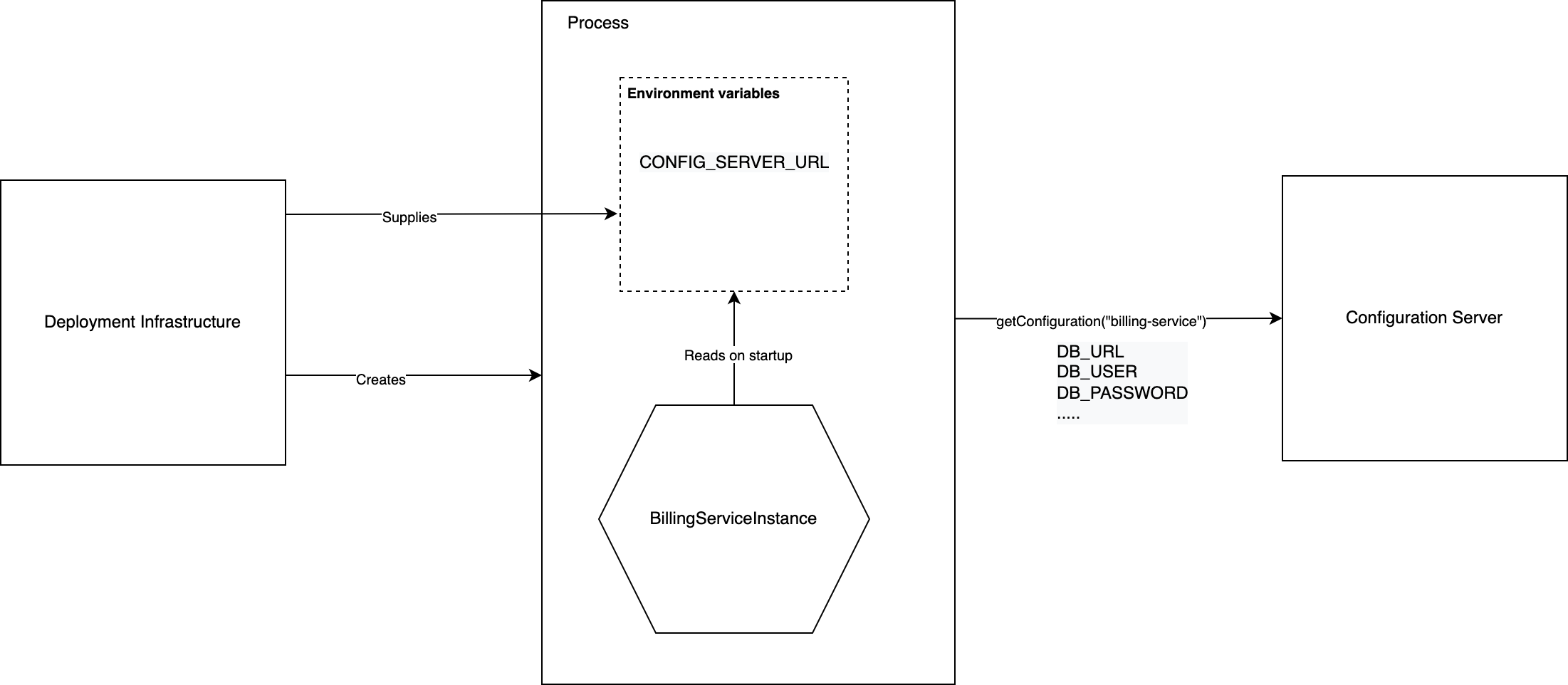
Pull Model
- In the Pull Model, service instances read configuration properties from a Configuration Server.
- A service instance queries the configuration server for its configuration properties on startup.
- The service instance needs to know the network location and possibly other configuration properties to access the configuration server. Such configuration properties are supplied to the service instance via a push-model-based configuration, for e.g. by making them available as environment variables.
- There are different ways a Configuration Server can be implemented:
- Version Control System (VCS), e.g. - Git
- SQL/NoSQL databases
- Specialized configuration servers like the Spring Cloud Config Server, and the Hashicorp Vault which is a store for sensitive data such as credentials.
- Spring Cloud Config Server is a server-client based configuration server that supports many different options for configuration property store, like VCS's, databases and Hashicorp Vault. The client retrieves configuration properties from the server and injects them into the Spring ApplicationContext - Read more about it here.
- Configuration properties across multiple services are centralized in the VCS's, databases, etc, and the configuration server provides a centralized abstraction for querying these configuration properties.
- The figure below represents how the Pull Model works:
Advantages and Disadvantages
Push Model
| Advantages | Disadvantages |
| Provided by the deployment infrastructure in most cases, so no/minimal development/maintenance/operational cost. | Reconfiguring a running service can be challenging. Once a service instance has read the supplied configurations, it may be not be possible for any updates to the configuration property values to reflect without restarting the instance. |
Pull Model
| Advantages | Disadvantages |
| A service can potentially autodetect updated property values, for e.g. by polling, and reconfigure itself. | The primary drawback of using a configuration server is that unless it is provided by the deployment infrastructure, it's yet another piece of service/infrastructure that needs to be developed, set up and maintained although open source projects like Spring Cloud Config Server make running a configuration server easier. |
Which one's better?
"It depends." - weigh feasibility, advantages, overall cost etc. for your particular use case and scenario.
